Overview
Large Language models (LLMs) are some of the most resource intensive applications to ever exist. This article follows from my prior article, going over some of the big advancements in AI over the last few decades. We have so many paths to explore in research right now, yet most of the attention (in America) is going towards building bigger data centers and power generation to feed the ever growing resource needs of generative AI training and inference. Let's go over why LLMs need so many resources.
LLM Terminology & Architecture
First, some baseline terminology:
Tokens are parts of words in the case of text based models. The tokens are turned into embeddings which are the high-dimensional vectors between [-1,1] for each "dimension" in the vector. Similar embeddings in the N-dimensional vector space are similar in meaning. Model weights are the pre-computed attention scores used in the attention function represented in that N-dimensional space. The attention is all you need paper gives us this nice diagram of an encoder-decoder model. The inputs and outputs are tokens in this diagram.
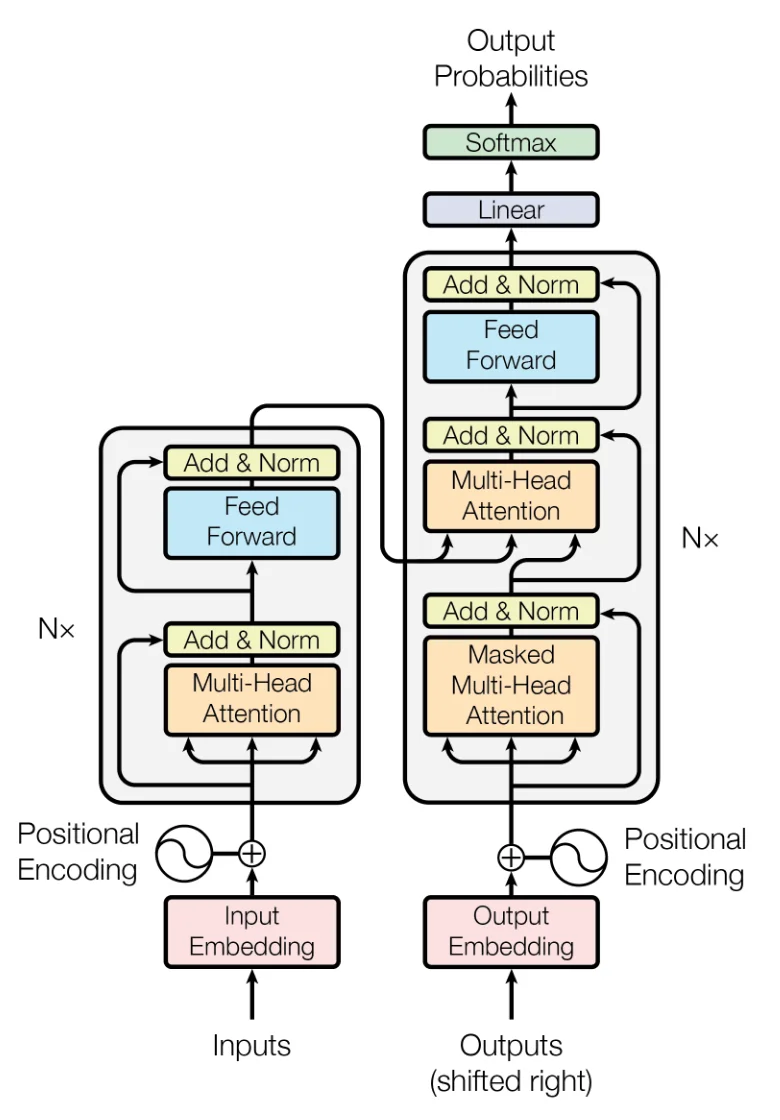
The encoder side of this diagram's main purpose is to take text and create a vector representation. Each token can look at any other token in an encoder, so the vector is computed by using all tokens at once within context. Encoders are useful for NLP tasks like sentiment analysis, or understanding where the context of each token matters relative to the others. Text embedding models such as those used in Retrieval Augmented Generation (RAG) systems are examples of encoder-only models where they take in text and transform it to the N-dimensional vector space by looking at all tokens in the input to transform to the vector space.
The really large chat models I am talking about like Claude, Gemini, and GPTs are decoder-only models. With Decoders, outputs become the inputs for the next token and that this is repeated many times for any singular instance you use an LLM. Decoder attention can only look at the tokens that come before to predict the singular next sequential token. To predict more, you run it more times. The main point of a decoder is to do token generation.
This might seem confusing that encoders are used for tasks like understanding, or sentiment analysis, but aren't these things that ChatGPT, Claude, et al can do?? What about a task like translation which requires both generation and understanding? These decoder only systems can do a pretty good job of translating between languages, but why? This is an emergent property from the scale of these systems and a testament to how good the pattern recognition is of very large decoder-only models.
Inference
Inference is the process of using the model to present output. The term comes from the Machine learning model inferring a conclusion from new input that is not in its training. This is a statistical process using the weights created in all the training steps. In the case of decoder-based LLMs, this generates the next token in the sequence originating from the inference input (prompt) and then does this over and over again until a stop token is generated. This is more expensive the larger your model is, regardless of how many of the weights you actually are using for your specific use case. This is also a sustained cost since you do inference every time you use a language model. The higher the cost, usually the higher the latency as well since you are billed based on the resource usage. This is why Haiku costs 5x less than Opus (Anthropic Pricing). While I don't know the exact numbers of parameters in Haiku vs Opus, it's safe to say there are far fewer in Haiku. That cost translates to the capital expenditure of the company in buying chips and building storage along with the runtime cost in power and cooling for inference.
Initial Training
Unsupervised Training is extremely resource intensive for large language models and happens in multiple pieces. First, is the self-supervised learning step. This is where massive amounts of unlabeled data is used to create the initial model weights based on its own self-reinforcing algorithms. This infers "features" from the massive text corpus. This is the core step to creating the billion parameter models. At the end of this, you have attention weights for the decoder model that predicts the next word based on the input of the other words. But this alone is rarely what you are interacting with as a user of LLMs.
Fine-tuning
Fine-tuning the model comes next. This is where labeled datasets are used, so there is some level of supervision in the training. This also changes the weights of the model, sometimes with certain sets of weights being frozen. The goal in this step is to align the model behavior with the behaviors shown in the training set. This is the step where the behavior of your large language models can diverge more drastically based on the provider. Research shows that LLMs despite being different tend to encode a similar semantic space. That said, if you have used ChatGPT, Grok, Claude, and Gemini you likely have noticed different outputs and ways of responding to certain inputs (like structured XML). This comes from the fine-tuning step. Each of these big provider models is likely fine-tuned on many different datasets or on very wide-reaching datasets since these providers are providing general purpose models. Fine-tuning techniques are varied, from reinforcement learning with human feedback (RLHF) which aligns the model behavior to the human preferences given through feedback to Anthropic's Constitutional AI techniques using RL from AI Feedback (RLAIF) in an automated way with less human bias.
Fine-tuning can also be application specific using a dataset of your own for your specific use case and reinforcing the weights towards the outcomes you want. This is a useful (albeit expensive) technique and generally offered by the model providers and other platforms like Amazon Bedrock.
Training is Expensive
All of these methods of training language models are very computationally expensive since each token in the training set is computed over and over again, across potentially billions of weights in each pass which are updated via back propagation. GPUs and other specialized hardware chips are very good at doing these computations in parallel, but given the size of these datasets and the number of passes through the training systems, this requires a lot of power to run all the chips and water to cool these systems. Additionally, fine-tuning a base model on your own data means you have to re-apply that dataset to a new model if you want to re-align it to your problem space. While you may not need to drastically change your labeled dataset, you still need to do the computations to change the newer model's weights. This can be an ongoing cost if you are adopting new models with any frequency.
Conclusion
The answer to why we need bigger data centers and more specialized chips comes from the way LLMs are built and run. It's inherent to the system to do tons of computation, thus requiring power, chips, and storage space to store the training sets required for this scale. Both the training and inference steps are computationally expensive and both are ongoing costs to develop and run these systems. At what point do we get diminishing returns?
In the next article, I will go over some Practical Techniques to Reduce LLM Resource Usage.