Model Context Protocol, A New Way to Expose Software
I recently started to work with the new (relatively, at least) open source standard put forth by Anthropic, Model Context Protocol (MCP). Simply put, it is a standardized way for large language models (LLMs) which function within the clients to access a server that provides both data and functions to the language model client. I am excited about this as it provides a way for developers to easily create tools that can work alongside LLM clients, creating a new type of user interface while giving a standardized way to ground language models with real, factual, consistent, and up to date information. This enables developers to enable new modes of interaction with custom software.
Building Blocks of MCP
MCP is composed of servers on one side which provide the tools, resources, and prompts to the client which discovers and orchestrates these tools using language models. I personally use the Claude.ai client as well as LM Studio which both support MCP (though note, the model itself must be fine-tuned for tool usage, so not all models in LM studio will work with MCP). There are two ways to connect to a server: 1. locally on stdio and 2. remote over https (usually with OAuth as part of tool setup). Using a server over stdio needs just a small configuration in the mcp.json file (usually) which can point directly to your build artifacts on your local machine.
Tools are essentially function calls to your server where the client (for instance, Claude.ai desktop app) orchestrates these calls based on the definition of the tools your server provides. This is a JSON Schema defining the tool name, description, and the input parameters. Tools provide functionality to the client quite like any sort of function call. Client generates the call, sends it to the server who then responds with human readable text.
Resources are read only data sources. They provide a URI structure to the client to request structured data. Think about knowledge bases or similar types of information that is read only and semi structured.
The third primitive, prompts, provide natural language templates that the model can use that might provide examples to call the tools or even function like small scripts leveraging the tools and resources to accomplish a task.
These are all listed by the client on startup which reads the JSON Schemas for tools and lists available resources.
Scryfall as an MCP Server
I built and open sourced a simple MCP server for my favorite card game, Magic: The Gathering (MTG) which I will use as a concrete example. There is a widely used site called Scryfall for MTG players to search for cards based on any manner of card properties from color, legality, text, or even by artist. Scryfall supports a complex set of queries allowing you to discover cards using a combination of terms. I personally enjoy building decks and looking for niche cards to support these creations. It's been on my mind to build a deck-building tool and MCP makes this easier to build than an entire bespoke tool.
To do this, I provided the tools:
search_cards- supports scryfall query syntax.get_card_details- gets details for a card by name.get_set_info- gets info about a set.get_random_card- gets a number of random cards. Fun, but not super practical.
The most important tools for my goals are 1 and 2. Enabling the language model to turn my natural language into multiple actionable queries against scryfall is incredibly powerful. Scryfall returns cards that match the query along with all their text, legalities, stats, special rules, etc. The second tool, get_card_details allows card names to be converted into the full text of the card which gives the language model context the full card text, legalities, stats, prices, etc. Here is what one of my more complex tool JSON Schemas looks like:
{
name: 'search_cards',
description: 'Search for Magic: The Gathering cards by name, type, or other criteria',
inputSchema: {
type: 'object',
properties: {
query: {
type: 'string',
description: 'Search query using Scryfall syntax. Supported prefixes: c:/color: (card color), id:/identity: (color identity), t:/type: (card/sub/supertype), o:/oracle: (card text), fo:/fulloracle: (full oracle text), keyword:/kw: (keyword abilities), m:/mana: (mana symbols), mv:/manavalue: (converted mana cost), power:, toughness:, loyalty:, devotion:, is: (card characteristics), f:/format: (format legality), e:/s:/set: (set code), r:/rarity:, a:/artist:, year:, game: (paper/arena/mtgo), usd: (USD price), eur: (EUR price), tix: (MTGO ticket price). Operators: >, <, =, >=, <=, !=. Use OR for alternatives, - for negation, parentheses for grouping, quotes for exact phrases, ! for exact names.'
},
limit: {
type: 'number',
description: 'Maximum number of results (default: 10)',
default: 10
}
},
required: ['query']
}
}
Additionally, I exposed the resources at the structure of scryfall://card/{cardName}, since these are read only resources that I want to be available to the language model. As an aside, this is not used in a local-only context as it reads from the cache which is cold on every startup, so no resources are listed (as far as I can tell). I did not expose any prompts in this service, though I may need to do so as I work with less capable models who do not infer the Scryfall query syntax from my description as well so that I may save typing on one-shot prompts which help less capable models make the function calls appropriately. You can find the full code on my public GitHub.
Why do this?
In my MTG deckbuilding process, I like to start with an idea of a deck in a particular format like Modern or Budget Vintage, then choose a set of colors to
The MCP resources and tools primarily serve to give the language model factual data about the cards. Without this, language models will still confidently tell you stuff, but it may not be true to reality and it certainly will not reflect brand new cards which are being constantly printed every couple months. Not to mention that pricing information, which changes daily for cards based on the secondary market, will always be incorrect. This ability to ground the language model in real information enables brand new ways to interact with groups of cards. Additionally, exposing search as a tool, lets the AI dig for cards as it needs to, and sometimes comes up with queries I would not have thought of, myself.
Example Scryfall LLM Chat
Language models provide a new kind of interface to manipulate data. You can further drill into the results that have come back (which might frequently be hundreds) using any of the card attributes: Price, Specific rules text, mana cost, etc. While these are searchable with the query syntax, being able to "chat" with the actual cards leads to interesting experiences. Take this example in the screenshot where I built a burn deck for a format where the entire deck must be under $30 (shoutout budget vintage).
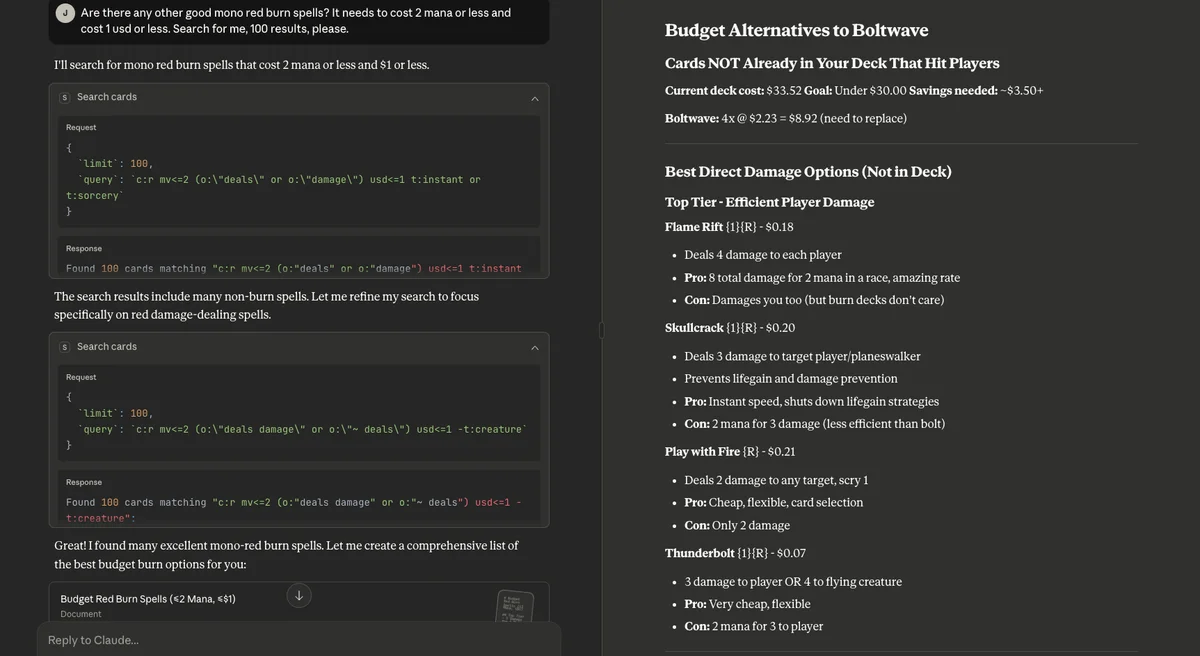
This shows the AI creating a search query based on my language. Then performing another search to refine the results. Finally, presenting them in a document, grouped by the attributes of the card and selecting the ones most relevant. Later in chat when trying to cut costs:

Since the context is already loaded with a hundred burn cards, there is no need to refetch the information, however, the AI is still able to make use of the factual data in context and provide reasonable suggestions to me. Now, the AI makes a mistake here because I have not explained the rules of the game. You are only allowed 4 copies of a card and the deck we are working on has 4 already of this card. I informed Claude of this:
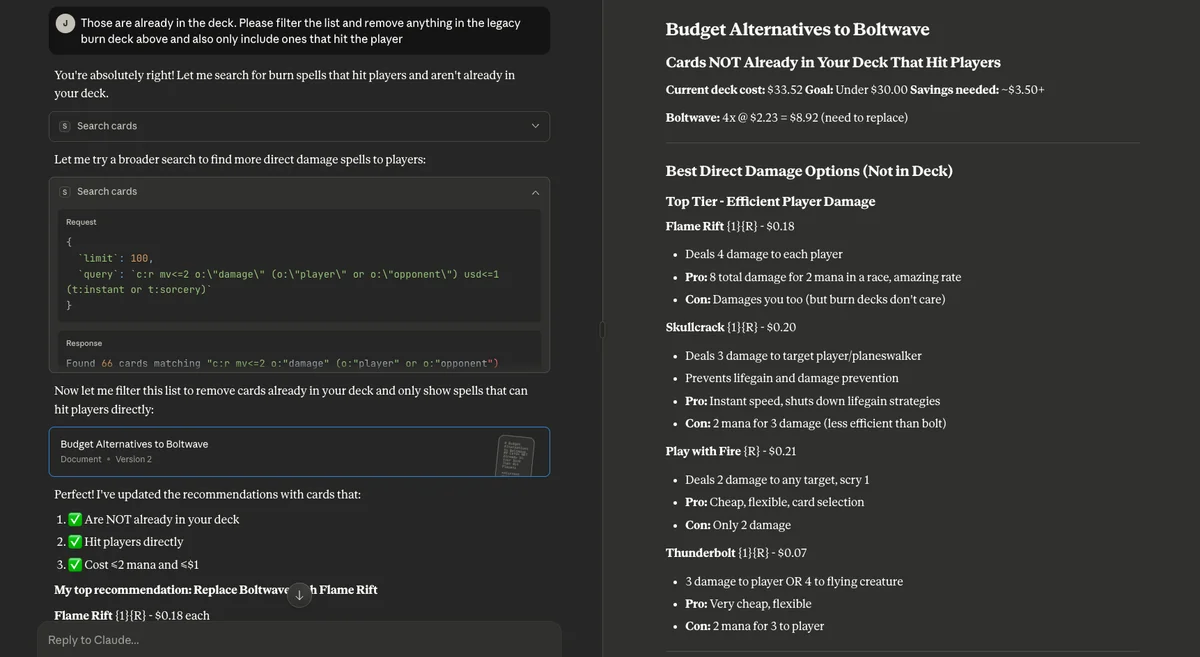
Since there is no scryfall query to "not use cards in Joe's theoretical burn deck", the AI devised another query that was more direct to what I was asking for (note, results count), then filtered out results already in the deck before presenting me options, yet again. Quite nice!
Why I am excited about this
To me, this represents a bit of a shift in my thinking towards new ways to expose software and build useful tools for people. Language models are fascinating in that they process text well by representing a semantic space and using this to generate plausible tokens in response to the input. They fail for most useful applications when they are not grounded in facts and are instead relying on their training data, alone for facts which will never provide generated text with substance. By grounding the LLM, you enable more useful applications to be built that are not simply the amalgamation of the text in the training (and your prompt), but instead uses up to date and reliable data sources. Additionally, proprietary data sources can be used as long as you are not using a language model which stores your chats and uses them to train future models...
The mechanics of exposing an MCP server are quite simple, and can be run totally locally to good effect. This enables quick experimentation for any API that can be accessed from your local machine. It's like writing any arbitrary UNIX program for your language model to use. There really seems to be endless opportunities in anything involving natural language (which is a lot of things). This ease of use and how well it works out of the box has me very excited about the possible uses as this protocol gets more adoption.
This builds on my excitement from initially using Claude Code which provides a very similar experience in that you are orchestrating context and guiding the language model to do some task. Managing context is the key in maximizing usage of any sort of language model tool. And yes, you can use custom MCP tools in Claude Code. More on that another time...
Dangers & Realities to MCP
Using MCP is a new thing but seems to be widely supported in language model hosting clients. One current downside is the friction to set one up. You need to go into settings, and know how to enable your MCP server. This might be from an HTTPS link for published servers or pointing to a program that exists locally. Additionally, it's unclear to me how well these tools will play together en-masse. I suspect they will be more useful in small groups to accomplish specific tasks like my deckbuilding tool rather than all together trying to accomplish every action imaginable.
I am not an expert with regards to risks, but some things stand out already to me. Perhaps it's a good thing there is quite a bit of friction to use an MCP server since you must trust the provider and their sources of their text, especially when there are actionable tools exposed. For one, indirect prompt injection is an ever-present risk and you must trust your data sources as well as the security of the MCP server (to prevent man-in-middle style attacks). Additionally, tools can enable quite literally anything and you are exposing that functionality to the AI client. You have to ask yourself, do I really want this to be enabled through ambiguous human text? These risks multiply as you use more tools at once since each one represents a risk of prompt injection which could cause other tools to be used when not intended.
The other danger has to do with exposing data you do not want to be public. While an MCP Server can safely deliver proprietary information to the Language model over stdio or HTTPS, be mindful of how your language model provider ends up using the chat logs. This is not a risk specific to MCP, but I want to point it out, anyways.
So far in my opinion, the tools I have used do a good job in surfacing these issues and enabling different levels of user authorization before using MCP (or turning off some MCP tools part of a server), but this is something to consider before building anything that causes physical changes in the world or some other "one-way door" type of action.
Conclusion
Despite some of the risks and realities to MCP servers, I am really excited at the idea of enabling new natural language interfaces to useful tools. I present the Scryfall MTG tool as a fun project enabling searching, filtering, and composing MTG decks using a natural language interface enabled through MCP. However, the real magic always has been in grounding language models and MCP is an nice mechanism to do this! Enabling actions on behalf of the user through a chat program has more risks, but I am excited on the possibilities here, too.
I am interested to see what the future may hold for this protocol and what other types of clients may emerge in the future. What do you think? Any MCP tools you have started to rely on?
Interested in integrating AI capabilities like MCP servers into your applications? Check out my consulting services.