Analytics for an AWS static site
Before launching this website, I had to make sure I had a plan to get analytics information in a privacy-focused way. I did not want to use any runtime JS to do this, nor rely on external services, so I built my own basic cost-effective and privacy-preserving solution. In this article, I will provide an overview of the basic website and how I accomplished this.
"Serverless" Architecture
I've been a huge fan of "serverless" architectures for years now. Serverless as a term is a bit of a misnomer as you always need some server to serve services (say that 5 times, fast). In the case of this blog, the architecture is simple and broken into 3 main pieces: Offline processing, "backend" code, and cloud infrastructure to serve pages to web clients and define the "backend".
Offline build process
Offline, I use a templating engine where I can write markdown, process this with a build script, and produce HTML files. This allows me to add custom markdown commands as I desire and gives me a place to modify the HTML to my liking through CSS or modification of the HTML elements during build time. I also use some hand written HTML templates for the basic parts of the site including pages like the contact page and I have partial templates to ensure consistency for the header and footer which are merged in during this build process.
CSS and other static assets like the favicon.ico, images and videos are all copied over to the distribution directory in addition to the rendered HTML templates and markdown files. This sets up the site locally, allowing me to test things locally, making sure the look and feel is to my liking before deployment.
Backend code
In addition to the static site, I also have another node package where I can write any runtime code. In my case currently, this is just an analytics processor as the website itself uses no runtime compute, part of what makes it incredibly cheap (I've spent <$0.50 in Sept for the website, so far). We'll get into what this does later.
Deployment and cloud infra
For deployments, I use Cloud Developer Kit (CDK) so that I can leverage AWS resources without ever accessing the console. CDK "synthesizes" the code into Cloudformation (CFN) templates and handles uploading this along with any assets such as code or static assets through abstractions called "constructs". Constructs are combined in "stacks" which are deployable bundles of related resources. I have 3 stacks, one for managing my domain cert (which I never want to delete, really), and one for the static site itself, and one for my analytics-related constructs. It lets me write all of the infrastructure as Typescript code which has a ton of benefits:
- repeatability to deploy new versions and to replicate this as needed (greatly beneficial on a team of developers)
- benefits of code. Since it is code, you can manage versioning of it with git, rollback bad versions, and do code reviews. Can be deployed through pipelines and other automation alongside runtime code if desired.
- ease of use. While there is a learning curve to CDK, and more generally CFN, when you get it, you never turn back. CDK is easier to use than raw CFN as it uses a programming language rather than yet another markup language (YAML) or JSON to define resources, letting you use normal code control elements like if-statements and loops rather than repeated markup.
- No clicking in console The AWS console changes over time and has a lot of annoyances (to me) in discrepancies in how you interact with various services. I hate clicking around to do things and giving the opportunity to miss something if I am repeating some setup. Maybe this is just a personal issue... 😂
- vibe code New benefit I observe, I can use Claude Code to help create these architectures. Though I caution you to review and understand what is produced and maybe set some cost limit notifications on your AWS account so you do not vibe your way to a huge cloud bill.
So CDK takes my offline produced bundle and built node backend code, then uploads this to the appropriate resources and creates or modifies any other resources defined in my stacks. AWeSome!
Architecting the solution
So, back to serverless architecture. Since this is a static site, I simply use cloudfront as a CDN service which serves all of my static assets and static HTML from an S3 bucket that is updated every time I deploy with the latest artifacts. This is highly cacheable, in most cases. No servers so I just pay for use on those two services. Additionally, I use Route53 to manage my domain which allows me to route the DNS to this Cloudfront address.
Cloudfront can emit metrics quite easily to Cloudwatch, the AWS logging solution:
const distribution = new cloudfront.Distribution(this, 'BlogDistribution', {
...omitted for brevity...
enableLogging: true,
logBucket: logsBucket,
logFilePrefix: 'cloudfront-logs/',
});
So here, I am emitting the "basic" metrics to the logsBucket (S3 construct). This gives me logs with the following fields:
#Fields: date time x-edge-location sc-bytes c-ip cs-method cs(Host) cs-uri-stem sc-status cs(Referer) cs(User-Agent) cs-uri-query cs(Cookie) x-edge-result-type x-edge-request-id x-host-header cs-protocol cs-bytes time-taken x-forwarded-for ssl-protocol ssl-cipher x-edge-response-result-type cs-protocol-version fle-status fle-encrypted-fields c-port time-to-first-byte x-edge-detailed-result-type sc-content-type sc-content-len sc-range-start sc-range-end
There are lots of these logs, so we need to make sense of them. This is where that backend code comes in. This code is deployed to a lambda that runs once per day to aggregate the logs into a much simpler format for me to use:
{
"date": "2025-09-18",
"totalViews": XXX,
"pageViews": {
"/tech/VibeCoding.html": XX,
"/index.html": XX,
"/": XX,
...
},
"referrers": {
"direct": XX,
"blog.joemocode.com": XX,
"www.linkedin.com": X,
...
},
"edgeLocations": {
"SEA900-P5": XX,
"PHL51-P1": X,
...
},
"statusCodes": {
"200": XX,
"206": XX,
"301": XX,
"304": XX,
"403": XX,
...
},
"processed": "2025-09-19T00:00:44.611Z"
}
These are then dropped into a new S3 bucket for analysis, one that has a longer retention period. This gives me an easier way to analyze the aggregate of all the traffic and only with the identifiers I care about.
A note on privacy: It's important to me to preserve my visitor's privacy, so I do not want to be storing fields like ip address for the long term (the logging bucket has a short retention period). I use EdgeLocations as a way to gauge where in the world I am serving pages to instead of IP Address so that I can still analyze traffic trends over time.
Visualizing the data
I am not a data engineer. However, I had to do an amount of this for my various roles at Amazon which is a notoriously data-driven company. One AWS cloud offering that I absolutely loved to solve ad-hoc analysis was Amazon Glue + Athena. You can apply the "glue" to an S3 bucket that contains structured data, and then run SQL queries in Athena, only paying for the queries you run. So for me, this is a perfect solution as I do not need to replicate data (which incurs movement and storage costs) and I can do any sort of deep analysis that I want.
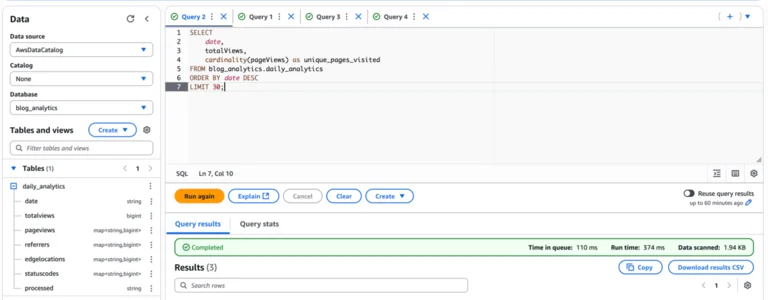
Now, anytime I want to analyze traffic, referrers, or just check views, I can run one of my queries in the Athena console.
Wrapup
This is how I check analytics without the need for any client side trackers, nor runtime JavaScript using an AWS cloud-centric approach. This solution is extremely cost effective for my situation while being expandable as I see fit in the future.
Need help implementing similar AWS solutions for your business? Check out my consulting services.