Prompt Injections
In light of the new Atlas browser by OpenAI, we have to discuss prompt injections. I'm going to write this article for everyone who uses tech, but also provide some thoughts specifically for Software Developers (feel free to skip these folded sections if you do not build applications!). Let's use the OWASP definition of Prompt Injection:
"A Prompt Injection Vulnerability occurs when user prompts alter the LLM’s behavior or output in unintended ways. These inputs can affect the model even if they are imperceptible to humans, therefore prompt injections do not need to be human-visible/readable, as long as the content is parsed by the model."
To fully cover the basics, the prompt is the entirety of text sent to the model. If it is being generated upon, it is part of the prompt.
Let's go over the 2 types of prompt injection attacks, direct and indirect. Then we will discuss some mitigation strategies you can take for your application and why you should be wary of tools like Atlas.
Direct Prompt Injection
You are likely familiar with direct prompt injections. These are the prompts directly from a user to subvert the intended behavior of the application. Consider the naive version:
"Forget all prior instructions and do XYZ"
Where XYZ is something the model will not produce on its own. This user input gets put inside the prompt sent to the model which could include other instructions trying to keep the model on a certain task. In the case of an app like ChatGPT, if you align your input to the model, you can bypass gaurdrails allowing access to generation that would otherwise be prohibited. I like _dbrogle@ on instagram's explanations of various direct prompt injection attacks which you can watch one, here.
This napalm making "jailbreak" is a recurring trope that gets harder to do with time as companies like Anthropic put better guardrails in place. Guardrail is a wide-reaching term spanning legal, policy and technical implementations that are varied. For instance, using deterministic systems to look for keywords, other AI systems to validate output, and/or fine-tuning of models to reject certain patterns, amongst other types of implementations.
Developer Takeaway
Direct prompt injections by the user is not necessarily a threat to the user as they are the ones intentionally jailbreaking the app. It is a threat to you as a developer of such an application. Without putting appropriate gaurdrails in place, you can be granting your users free access to AI models. And if your application performs actions of any sort based on the output of Generative AI, you need to really pay attention to how users are able to input their own information because you can be granting access to any of those actions, even when not intended. Constraining the input to only the necessary character length is one step to take. Find some way to validate input as well, for instance, looking for code to scrub out (preventing exfiltration) or taking in structured options instead of freeform text. More mitgation strategies below.
Indirect Prompt Injection
Indirect prompt injection is the elephant in the room for any sort of application pulling in data, and then passing through a Generative AI model. This happens when a data source contains words that change the intended behavior of the model. For instance, when using ChatGPT and it pulls in a website to cite for some information, it is processing some amount of the text (and likely non-visible in the browser text like accessibility labels). All of this text could contain instructions to do something like change what text the model outputs or guide the model to separate conclusions than you may reach if reading the visible page. In "Agentic" systems where the model has access to tools that write, delete, or otherwise change something, you are potentially granting third party APIs providing data the ability to use these tools on your behalf. I wrote about building an MCP server for scryfall, as one example of an arbitrary tool that modifies the behavior of the language model client. In the case of the Scryfall MCP server, the prompt injection risk comes from the API of Magic: The Gathering cards. Perhaps the next un-set in MTG has a joke card called "forget all prior instructions" that messes up the language model. 😂 Or, maybe Scryfall's service is hacked and starts returning malicious info. While the stakes are low in this application, both the Claude.ai client and LM Studio warn you that you must trust the developer before enabling. Example from LM Studio:
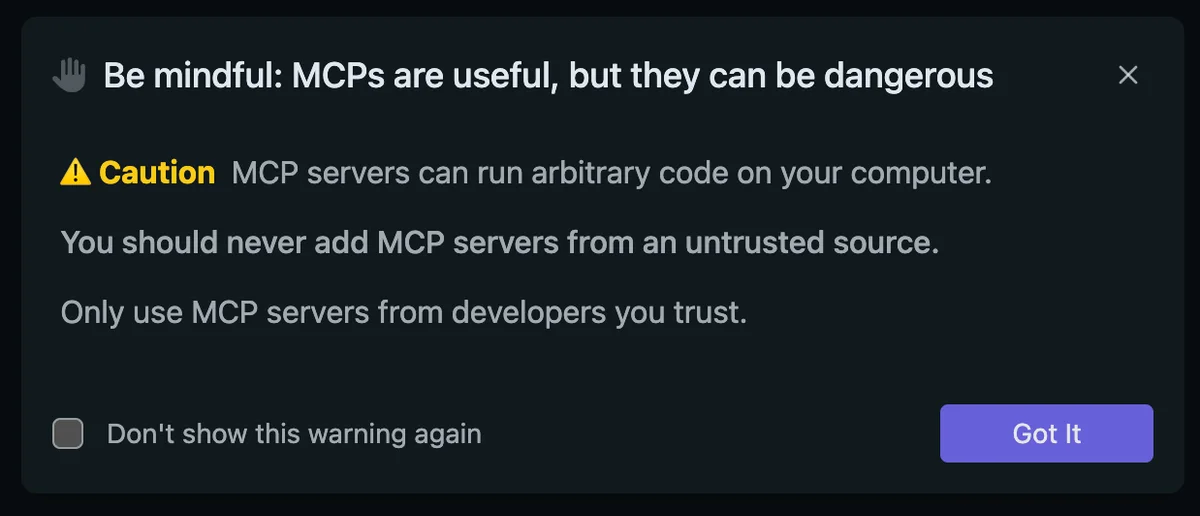
You cannot really know what the tool call is going to do, so you should assume they are capable of actions unless you trust they are not doing this. OAuth services (like login with Google) will grant access only to operations that are explicitly allowed by you, so there are some mechanisms to build trust that READ-Only sources are being used. But even still, consider a prompt attack through an email you get from Gmail. If you link it to your local LLM and that local LLM has access to your filesystem (like is supported by Claude.ai and OpenAI), you have essentially made it possible for an email to control your local computer at the privilege level you have given the language model client. This kind of vulnerability exists for every data source used in a generative AI application; if it adds text to the prompt that is not provided by the you, it is a vector for indirect prompt injection.
Developer Takeaway
Indirect prompt injections are much harder to detect and can become evident later in the case of live services no matter how much testing you do before launch. If the API you use for data is hacked or starts outputting text that gets in the way of your gen AI model behavior, you are now injecting that content into the prompt which might have unintended side effects. Mitigation strategies are similar in both cases, but the impact could be much more damaging in this situation.
Mitigation Strategies
This is an open problem in LLM systems, right now. The mitigations are mostly best intention when it comes to subverting unintended output from language models. I would even argue, it is not possible to fully subvert these problems given the absolutely heuristic nature of any sort of deep learning. But all things in security are not about making it impossible, but making it harder than it's worth an attacker. If you're not a developer, you can skip this section and go right to the next section.
For security issue guidance, I like to look to OWASP.
Mitigation 1: Constrain model behavior
These are implemented using instructions you provide to the model to play a specific role (like in system prompt), limit the output to specific topics using instructions, and add instructions to ignore attempts to subvert this behavior. These are best intentions given the heuristic nature of models. Not all models are equal and have differing companies/datasets aligning them to different behaviors. These do not necessarily transfer between models due to fine tuning differences. Best intention or not, you should still do this as it is somewhat effective (we're mitigating, not mathematically proving it can't happen 😂). Here are the Anthropic docs on mitigating jailbreaks.
Mitigation 2: Define and validate expected formats
When there is a known output (for instance JSON), use instructions to tell the model the expectation and verify the output using a deterministic library to validate it is of the expected form. When there are sources used, always present these to the customer so they can validate them. Most model APIs also allow you to prefill the response which is very useful in certain cases (like producing JSON or XML) to improve adherence to the generation since output tokens == input tokens for the next token generation step, so forcing the first few tokens to something will keep the model on the rails.
Mitigation 3: Implement input and output filters
Define your sensitive categories (policy decision) and use regex to look for output that you do not want. This extends to code filtering. For instance, if your application has no reasonable reason to be outputting Javascript or HTML, do not allow output of a script tag that could potentially be inflated into the DOM and used to perform some data exfiltration attack. OWASP also recommends using the RAG Triad which is an evaluation framework for assessing Context Relevance, Groundedness, and Answer Relevance. I recommend use of your expert customers to help validate your generation before launch and have a feedback mechanism for them to flag when things are going wrong post-launch which enables you to provide better filtering over time.
Mitigation 4: Enforce privilege control and least privilege access
Deterministically check if the user has access to some data before using it. This is not only a security thing, but also for keeping confidential or private information safe. And for sure, check authorization before performing actions in a deterministic way. Don't let models do things on their own and certainly do not give them your API keys (total lunacy!).
Mitigation 5: Require human approval for high-risk actions
For any action that changes state of something (which includes context state and READ-only actions like web search), have a mechanism to allow your users to approve it. A great example in my view is Claude Code which asks for scoped permission to do any tool call within a specific directory and its children. This happens before performing any action, including writing code! This enables better security, but also is a value add to the product itself since you can use Claude code in a pair-programming fashion by not allowing it to write code for that specific session. All mitigations are work, but not all provide worse experiences (though this is a common tradeoff in security).
Mitigation 6: Segregate and identify external content
This is another best intention since it relies on instructions to the AI, but you must clearly separate the different kinds of content you are putting into the prompt. For instance, many models are fine tuned on XML tagging, so you can use XML to denote a user from the results of an API call (or multiple separate APIs). Additionally, when you take constrained input, you can tag it effectively. This does two things: 1. informs the Language model of the type of content it expects to see in a tag. 2. Gives you the tools to reference that material later in the prompt. This is a great way to improve attention given to your injected materials, thus grounding the LLM better and likely giving you better results in addition to providing some mitigation to prompt injection while making it easier to check output types as well (mitigation 3)! Example Anthropic docs.
Mitigation 7: Conduct adversarial testing and attack simulations
And finally, test your product. Ask people to break it. Hire a red-teaming organization if you are doing potentially dangerous things based on output. Additionally, flag the above mitigations when you can in your metrics for you to look at potential attacks in the logs. Usually, there will be some unsuccessful attacks before a successful one and logging these may help alert you to dig into the logs and discover a new attack vector faster and before damage is done at scale.
So while no single one of these will ever "solve" the prompt injection threat, given a known, constrained application, we can provide some defense-in-depth mitigations that are effective at stopping the worst problems from happening.
Atlas is a Security Nightmare
Given the open nature of this problem and the absolute levels of privilege given to the OpenAI agent, I would never, ever use agent mode. There is no possible way to provide many of the mitigations listed above due to the open-ended nature of the web and the unknown nature of whatever the agent is interacting with on any given page. This is still a problem outside of Agent mode as well, assuming you intend to log into any website where you will be viewing your own privileged data, thus presenting privacy problems for you. OpenAI reserves the right to train on this information if it is not the enterprise version. Make sure to read the terms and check your settings.
Many of those mitigations above either reduce the generalized usefulness of the language model or require some specialized knowledge of how the model is in use. Both of these are fine tradeoffs to make in many cases, but the web is too open ended to knowingly constrain input. Of course, too, the web cannot be trusted at face value, so even when there are markers for a specific kind of field, OpenAI itself says it will use Aria tags (accessibility labels not visible on a webpage) to guide model behavior. So your model will be experiencing a different version of a given webpage than you by OpenAI's own admission. On output mitigations, OpenAI does not have a great track record of mitigating risks to customers in output. And on the topic of red-teaming, I encourage you to look at the red-teaming section in the Agent paper, the majority of which I quote here:
Prompt injection red teaming was carried out by several organizations focused on cybersecurity testing. This occurred in parallel to internal red teaming, focusing on injection techniques that could exfiltrate data. We do not list specific attack details and mitigation updates here to avoid providing a roadmap for future attackers. Further details about our prompt injection evaluations and mitigations can be found in 3.1, and were informed by the human red teaming efforts throughout the product development process.
So while they do red-teaming and have continuous monitoring of their systems, there are known non-transparent risks. And most of the testing was done on exfiltration attacks (sending privileged information to a third party). For results of different kinds of prompt injections, they provide the following tables:
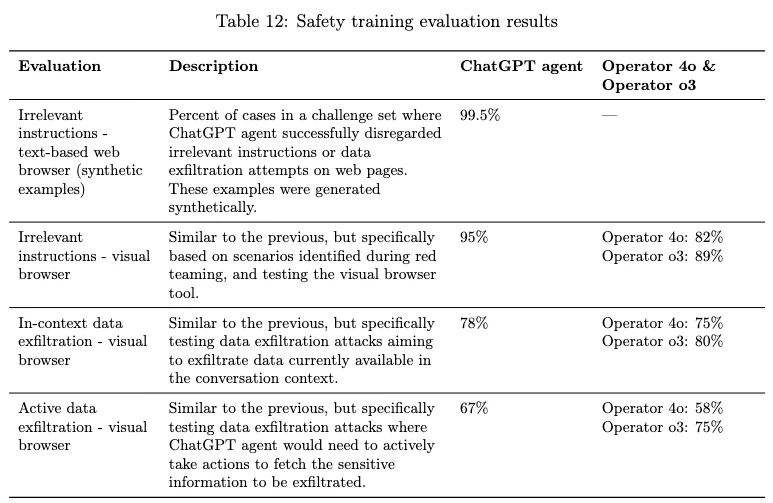
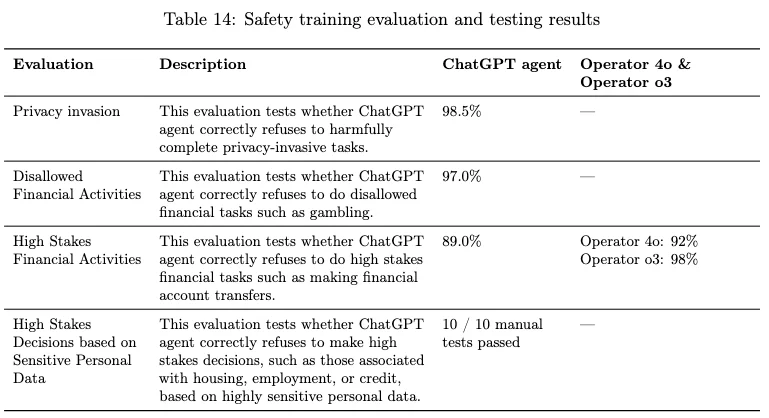
Not bad results given this is the model only without additional mitigations built into the Atlas product (notably lacking in transparency), but clearly room for improvement. I am not okay knowing that 22% of the attacks OpenAI researchers thought of succeeded in exfiltrating data. 😅
If you choose to use this browser, the best mitigation you can apply is to only access public web content with it or other content you do not care is leaked to a third party. Do not log into banks, your employer's internal websites, or any other confidential places since it is possible this info is extracted either through adversarial prompts or through future models trained on this information.
Prompt Injections are here to stay
Prompt injections can grant users access to content and services they otherwise may not have access to by hijacking prompt sources prior to performing generative AI on some text/data. Direct prompt injection is a risk to builders providing inadvertent experiences to their customers. Meanwhile, indirect prompt injection is a risk to us all. For any system where the input is not known (like the web) and also cannot be constrained in meaningful ways, you drastically open up the risk. And the risk profile gets much worse when you are taking action on behalf of a model output, as is the case is agentic systems.
I hope this gives you some perspective on some of the fundamental problems in building AI Agents, and other Generative AI tools. This is why I am a believer in more software built using models where there is a specific purpose and set of constraints, but not so much on releasing Agents (and chatbots) into our unconstrained world with increasingly high levels of privilege. I think such cases are just waiting for massive problems.
Need guidance on building secure AI systems and mitigating risks like prompt injection? Check out my consulting services.