I decided to make one of my personal Model Context Protocol (MCP) tools available as an application for others to use without the need for any developer-focused setup. In part, I wanted to use this on my phone without needing to have local databases. As another part of this, I wanted to improve the tool itself. I wrote about the initial tool and my thoughts on MCP in general in the blog, Model Context Protocol: A New Way to Expose Software.
Let's go into how I broke down my Scryfall MCP project to create a hosted application while turning some of the non-deterministic actions into deterministic actions and why I made these changes.
Scryfall MCP Judge Support
First, I took the existing open source Scryfall MCP tool and added some more tools and a prompt in order to make it capable of answering Magic: the Gathering (MTG) rules questions. The tools in question were the following:
- get_rule - Get a specific rule or subrule by ID.
- search_rules - searches for rules based on rule ID or other indexable characteristics.
- get_glossary_entry - words and phrases with special meaning in the game like: "move", "activate", "multiplayer game", etc.
- get_keyword_ability - Game abilities on cards like "haste", "scavenge", "companion", etc
These tools were created by parsing the MTG Comprehensive rules document which is the de-facto rulebook for all elements of the game, used by judges who are ordained by Hasbro to enforce the rules of the game. Every competitive event has judges, sometimes multiple judges with a head judge that gives the de-facto rulings for the tournament. Each of these operations uses a section of the rulebook to power the MCP tool. I put these in a local sqlite db for the initial MCP prototype.
In addition to those tools, I exposed a prompt which described how the tools should be used to come up with an answer to the question. This took in a question argument that represented the user prompt:
Markdown of MCP Prompt
You are acting as a Magic: The Gathering judge. Answer this question with complete accuracy by following these steps:
**Question:** ${args.question}
═══════════════════════════════════════════════════════════════════
**REQUIRED RESEARCH STEPS (complete ALL before answering):**
1. **Look up all cards mentioned:**
- Identify every card name in the question
- Use get_card_details() for EACH card to get exact oracle text and card properties
- Pay attention to types, subtypes, abilities, mana costs, power/toughness, etc.
2. **Look up all keywords referenced:**
- Identify every keyword ability mentioned or implied
- Use get_keyword_ability() for EACH keyword to get official comprehensive rules
- Even if a keyword seems simple, you MUST look it up
3. **Look up specific rules if mentioned:**
- If the question references specific rule numbers (e.g., "702.9c", "117.3a"), use get_rule() to fetch them
- Always include subrules when getting a rule
4. **Look up unfamiliar terms or concepts:**
- For any game terms you need clarification on, use get_glossary_entry()
- If the glossary doesn't have the term, use search_rules() to find relevant rules
- Terms to watch for: target, choose, may, must, destroy, sacrifice, exile, cast, play, etc.
5. **Analyze for complex interactions:**
- **Recursive triggers check:** After each triggered ability resolves, ask "Does the resolution of this ability meet the trigger condition for any ability (including itself)?"
- **Type-change analysis:** When a card's type changes (e.g., artifact becomes land, creature becomes artifact), verify:
* What new types does this object have?
* Do any of its existing abilities now reference its own new types?
* Example: If an artifact becomes a land, check if any of its abilities say "whenever a land..." or "lands you control..."
- **Self-reference check:** When an object has abilities that reference object types, ask: "Is this object one of those types? If yes, does the ability affect/trigger from itself?"
- **Multi-pass simulation:** Trace through at least TWO iterations:
* First pass: What happens immediately?
* Second pass: Does anything that just happened create new triggers/effects?
* Continue until no new triggers occur or loop detected
- **Infinite loop detection:** If an ability could trigger itself or create a chain that leads back to itself, state:
* "This creates a mandatory infinite loop" → "Result: Game ends in a draw (Rule 104.4b)"
* OR "This is optional, so player can choose to stop"
6. **Answer the question:**
- Think step by step through EACH iteration of triggers and state changes
- Now that you have ALL the context, provide a complete answer
- Cite specific rules (e.g., "According to Rule 702.9c...")
- Quote exact oracle text when relevant
- Explain step-by-step how the interaction works
- If there are multiple scenarios, address each one
═══════════════════════════════════════════════════════════════════
**FORMAT YOUR ANSWER:**
**Research:**
[List what you looked up - cards, keywords, rules, glossary terms]
**Answer:**
[Your detailed answer with rule citations and oracle text quotes]
**Ruling:**
[Clear, concise summary of what happens]
═══════════════════════════════════════════════════════════════════
CRITICAL REMINDERS:
- DO NOT answer from memory - you MUST look up everything first
- ALL cards mentioned must be fetched with get_card_details()
- ALL keywords must be fetched with get_keyword_ability()
- Cite rule numbers for all claims about game rules
- Use exact oracle text when referencing card abilities`
MCP Limitations
After fixing some issues in the parsing system, I was able to test this tool to good effect within Claude.ai desktop as well as LM studio, opting for mistral small models for the latter. In both cases, I got good responses by grounding the LLM with these tools to get the information needed to give rules clarifications and explanations of complex card interactions, but the responses were not perfect. Frequently, for very complex interactions, I had to probe it with specific clarifying questions to get the correct ruling. Ultimately, I want this tool to be useful for someone with less knowledge of the game who maybe does not have access to a proper judge or even knowledge of the comprehensive rules system.
LLM clients give the benefit of ease of use and followup questions, holding context across the session, and allowing all of the tool calls for each iteration. However, MCP itself requires setup by the user since you have to add the server to the MCP list. The second problem was that my MCP service is not hosted anywhere. And last, this really should be a purpose-built tool. While there are some other situations where looking up MTG rules might be helpful in a generic sense, it's more likely to get value from a tool like this by having a dedicated way to interact with it, making it so you do not need to have a specific language model client for interacting with a virtual magic judge. This also enables some affordance to mitigate issues related to indirect prompt injection. It was after realizing this that I took the prototype to the cloud.
Hosting on AWS
I created a fresh AWS account, new set of credentials, and bought a domain from cloudflare to create app.mtg-judge.com. This contains the newly hosted application version. I initially started by trying to host the MCP directly as a "quick win", but that was quickly spoiled by the fact that Anthropic's API does not allow for MCP. While I could host just the MCP server, ultimately, I wanted to trade some of the non-deterministic tool calls to deterministic context building, anyways.One example is that glossary terms can simply be detected in the prompt or in the tool call results and deterministically defined without need for special vector indexes, LLM inference, or any other "AI" techniques. This is also true for rules and keywords. A purpose-build application is the best way to do this. Utimately, I ended up with this:
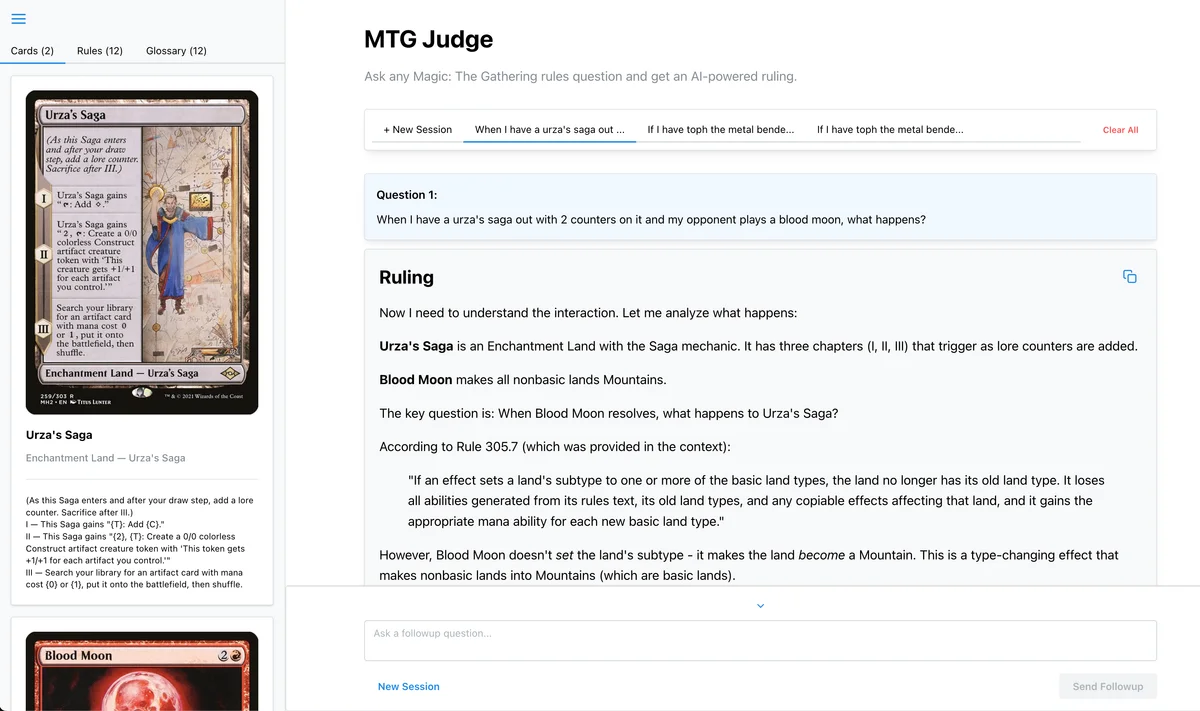
Creating the DB
I opted for a DynamoDB table to hold the comprehensive rules including keywords, glossary definitions, rules, subrules, and the relationships between rules, subrules, and glossary items. I parsed the same file with similar parsing code to create this database. This only needs update when 1. bugs are found or I need a better data structure, 2. the rules of the game change which does happen, especially with the influx of new sets with new keywords, but this is only a few times per year. For now, this will remain a manual process to keep it up to date for the ~7 times per year that new cards (and mechanics) are released.
Defining Tools
In order to reduce the amount of tools that were inferred by the LLM, I opted to use deterministic string matching over most of the tool calls for all of the tools I mention above. I kept only tools for scryfall search and get card text by name. This allows the LLM to infer the MTG cards from the prompt from the user, and enables it to search for cards that might meet some criteria. Since there are over 27k cards in the catalog, with more added each year, it's not reasonable to search for all of them via text, especially accounting for user spelling errors and such making it a very hard problem. Glossary terms, rules, and keywords are all easily parsed verbatim, appearing within the card text and the user prompt. I search all of these areas in the prompt for the special terms and fetch related concepts like rules as needed, opting to keep the rules structure to provide better context to the LLM. Then, these are fed in (or back in, after a tool call) to the LLM for inference.
Claude Tools Definition JSON
[
{
name: 'search_cards',
description: `Search for Magic: The Gathering cards using Scryfall syntax.
Common search operators:
- t: = type line
- o: = oracle text
- c: = color
- mv: = mana value
- pow: = power
- tou: = toughness
- set: = set code
- r: = rarity (c/u/r/m)`,
input_schema: {
type: 'object',
properties: {
query: {
type: 'string',
description: 'Search query using Scryfall syntax',
},
limit: {
type: 'number',
description: 'Maximum number of results to return (default 5)',
default: 5,
},
},
required: ['query'],
},
},
{
name: 'get_card_details',
description: 'Get detailed information about a specific Magic card by exact name. Returns oracle text, mana cost, type, power/toughness, legalities, and pricing.',
input_schema: {
type: 'object',
properties: {
name: {
type: 'string',
description: 'Exact card name (e.g., "Lightning Bolt", "Mana Drain")',
},
},
required: ['name'],
},
},
]
Tools are defined in a tool definition block (shown above) which is very similar to MCP tool definitions and fed into the API call alongside system prompt, temperature, max_tokens, etc. I set a reasonable model max token value to mitigate other adversarial attacks, and utilize a prompt similar to the one I shared without the extraneous tool definitions and with some XML-based instruction since I use XML to format the different data like rules hierarchy, keyword definitions, and glossary terms in addition to any cards that are fetched during the process. XML, suggested in Claude's documentation, is useful for structured input since it notifies the model about different types of data in a semantic way which gives more affordance to the model to apply guardrails in addition to improving your ability to write detailed prompts. With tools, the LLM will occasionally pause inference and send a request back, asking for the tool call result before continuing inference. This happens in a few turns until the result is back in its entirety.
Long Running API Problems
I tend to opt for Lambda + API Gateway for my API needs for any sort of web application I build these days. It gives great segmentation of data management since you only grant IAM access to the databases truly necessary to handle the requests that lambda responds to. Likewise you get blast radius segmentation, too, so if there is a bad code deployment, only the lambda that runs that code path will be affected, making it less likely for your entire server to crash because of one bad code change. With a container or ec2 service, you are granting all code paths the access to all databases that instance accesses and the ability for unrelated access patterns to use too many resources and affect other paths. This come at a slight expense of cold start for entirely fresh requests. Cold-starts can take 100ms, and are a side effect of the pay as you go nature of Lambda where you only pay for the compute you use which is great for low traffic websites while allowing them to handle large bursts of traffic since Lambda can quickly scale to 10k concurrent processes. At a steady rate of traffic, cold start is not a problem since Lambda containers can last for 10+ minutes, even when not in use. Now, we still have an issue with this architecture since APIGateway cannot hold a request for more than 30 seconds.
Since we are using a multi-turn LLM call, this can take more than 30 seconds which is the APIGateway limit for HTTP responses. To solve this, I have the handler invoke another lambda that does the processing of the query and handles the LLM call while updating a session dynamoDB table with the result. The frontend then gets a 202: Accepted response from the first call (assuming all went well). The frontend app then knows to poll a second endpoint which will hold the response for that UUID. This allows for very long timeouts while giving the customer a UI that shows something is happening. This gives the side effect of showing me the prompt and response which I hold onto only for 168 hours (DDB auto deletion rocks). Also, I can easily add ability to share rulings, when I so choose.
Putting it Together: GUI
After solving the long running API problem, the tools determinism issues, and resolving database loading and management differences, I could focus attention towards the UI. In an MCP server, you see the tool call results as a blob of text in a collapsible subsection within the response. This is not an ideal way to look at structured data, especially when that data contains image URLs and other text that can be rendered more effectively. I did this, by creating a collapsible side-bar that can display image URLs from Scryfall, show the glossary and keywords used in the request, and link the various rule references to a more focused subset of the rules. Also, wherever a rule is located, I can then make this clickable to scroll to the relevant rule or sub-rule in the sidebar, making it easy to correlate the response and prompt inputs to the actual written rules. This is way more effective way to look at the context that was used than MCP responses in an unformatted JSON blob embedded within text.
While I had to build this GUI specific to the data, the bigger point is that I was able to do these customizations to provide a better experience without my customer needing to run local servers and databases along with a specific Language model client. This also breaks me out of the chatbot pattern. I still allow followup requests, but I have full control over the prompt and context and need not be confined to chat, alone.
Future Work
UX Improvement - Add Deterministic Card Selection
There are ways to fully eliminate the need for these last tools by allowing the user to pick cards by directly using Scryfall search. This would likely reduce my token usage with Anthropic's API, but it would not provide the same experience as asking your friendly neighborhood MTG Judge an open-ended question. Maybe, I'll add this as an optional feature in the future in case I end up having issues with the model missing the cards being asked about which has not been much issue with Anthropic 4.x models, so far. In general, the UX can be improved in style and usability.
Bugs and Better Prompts
There are some bugs to find and resolve, too. I'm quite certain that I can improve how I am parsing the comprehensive rules and loading the database. The way that some of the baseline information for the game is loaded can be improved, too. There are some special sections of the rules that are not being well grounded in the application that might need special logic similar to glossary and keywords since they are often relevant but rarely cited by number. Will do my best to make this deterministic and minimal in the instructions without bloating them much more than they already are.
Prompts can be tuned as well. Turns out "prompt engineering" is useful for purpose-built LLM systems. I want to note that prompts are specific to your model you're using which is part of why I never reach for frameworks that add what I beleive to be needless abstractions. It's tricky getting a prompt that works well while minimizing token bloat and it will always be specific to your runtime model.
Authentication
I might have to add some authentication, at some point. This is currently being offered for free to anyone who has the URL and the API has no authentication or authorization, either. If this becomes widely used, I will have to add some form of payment to it (perhaps with a free tier) which will require authentication, so that I can easily rate limit users and identify people who are abusing the system. I have a limit on the tokens that can be processed as well as the lambda run time, so there is minimal damage that can be done at the moment. That said, I will keep monitoring for bad actors!
Pro tip! For all your cloud services, make sure you have price alerts on at thresholds you are comfortable with.
Other Prompts
I love designing new decks in MTG and it was the original catalyst for building the Scryfall MCP. The data grounding in this application is additive to this, so it can be reused with other prompts. I have some UX work to do and other tools to think through (like a mana-base optimizer), but do expect a new page in the future focused on this. This is a work in progress.
Learnings from Converting MCP Server to a Standalone App
MCP is a great tool for prototyping Language Model applications, but I am still not convinced it is useful for wide adoption, even ignoring the indirect prompt injection problems. While you can host MCP servers and enable distributed LLM clients to call the tools, get results, and infer responses, I believe that most applications built on top of LLMs will benefit from having bespoke ways of interaction and displaying data; ways which put humans in-the-loop. In this example, I leveraged the LLM for inferring MTG card names and rulings based on the input from a user while using simple, deterministic string parsing to check for keywords, abilities, and specific rule ids to ground the LLM. I leaned on the strengths of language models for language processing and generation of responses while minimizing the non-determinism with simple string matching. In converting this from MCP to a proper application, I could improve the transparency of the data being displayed through better GUI and mitigate problems from prompt injection simply by having a properly scoped application that uses an LLM rather than an LLM that uses some new data sources in an environment that is otherwise unknown and could contain many other external sources for prompt injection.
If you play Magic: The Gathering and use this tool for any rules clarification questions, let me know how it goes! Feel free to reach out on my contact info page or anywhere else you know to reach me.